


The IPP: from Summit to Science
February 14th, 2011 by royhendersonWith a 1.4 billion pixel camera, and a mission to cover as much of the sky as often as possible, itâs easy to see why the Pan-STARRS 1 survey produces a lot of data (enough to fill a thousand DVDs each night). But how does this avalanche of raw images get transformed into something useful for real science? The answer comes in the form of the Image Processing Pipeline (IPP), a key Pan-STARRS subsystem that has the unenviable task of storing, processing and distributing data to scientists around the world.
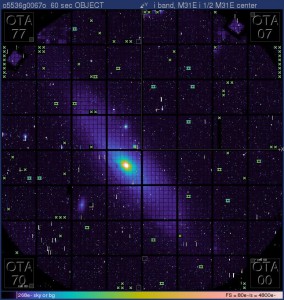
A raw exposure of the type processed by the IPP. This image is of the Andromeda spiral galaxy (M31). Each Pan-STARRS image is comprised of 60 separate CCD chips, themselves made up of 64 individual cells 600x600 pixels in size. Credit: PS1SC
The data volumes are huge: an average of 500 images are taken each night, each nearly 1.5Gb in size. Once copied over fiber-optic cable from the summit of Haleakala, processing begins using a cluster of 87 computers at the Maui High Performance Computing Center (MHPCC). Because the IPP needs to keep a backup copy of all raw images, as well as producing products from each, a huge storage capacity is required. Currently, over a petabyte of storage is available - enough to store 13 years of high-definition video.
The early stages of the pipeline clean the raw exposures and catalog the detections recorded in each frame. A detection is anything that stands-out over the background of the sky, and so most are the result of light from stars and galaxies. But there are also a variety of non-astronomical detections that must be filtered out of the data, including those arising from imperfections in the camera, passing satellites, even exotic events like cosmic rays.
One method to minimize the effects of camera faults is the use of dark frames. These are images taken with the camera shutter closed, and are essentially photographs of the imperfections that will ultimately show up in all images. Dark frames, usually taken before observations begin for the night, are used to subtract away these unwanted features from the actual science images taken later.
Other unwanted detections are harder to remove. Cosmic rays, for example, are high energy particles from distant space that hit our detector an average of 2000 times per exposure, and have a bad habit of looking like astronomical objects, such as comets. Sophisticated algorithms are used to weed these out, with every detection given a likelihood of being a star, galaxy or cosmic ray. For bright detections, these likelihoods are very accurate, but at the fainter end the error margins increase.
As well as nice clean images of the night sky, the IPP must also catalog the properties of the astronomical objects detected in each image. Broadly speaking, this breaks down into astrometry and photometry. Astrometry is the measurement of the positions of objects on the sky, whereas photometry is the measure of their relative brightnesses. It is this information that will ultimately make up the Pan-STARRS Survey Catalog, with accuracy improving over time as more and more sky coverage is obtained.
With images cleaned, and detections cataloged, the end result of this first part of the pipeline is what we call warps. These images have been adjusted to the coordinate system of the sky, rather than the camera. Warps are then used in combination to create new images, such as diffs and stacks.
Each night, PS1 takes pairs of images of the same part of the sky an hour or so apart. This enables the IPP to hunt for transient objects. Transients are objects that either change in position or brightness over time. Asteroids and comets are examples of the former and supernovae (exploding stars) of the latter. By taking the image pairs, and subtracting them one from the other, features common to both (the static stars and galaxies) are removed, while the transients remain. These diff images are the main product of interest to the Moving Objects Pipeline (MOPS) subsystem, which uses them to locate objects that may be on a collision course with the Earth.
Other scientists are interested in the static sky, and for this, the deeper the better. Pan-STARRSâ sensitivity means that it can see very faint objects in every frame, but extra depth can be obtained by adding together, or stacking, images taken of the same region of sky. Contrary to diff images, stacks remove all transient features, while also reducing image noise (random variations across the image) and strengthening the signal of the real astronomical detections. This is what is meant by improving the ‘signal-to-noise ratioâ, and helps reveal objects that may have been unnoticeable in the single exposure frames. The more images that are combined, the deeper the resultant stack and the fainter the objects that can be resolved. Ultimately, when the Pan-STARRS survey is complete, the IPP will produce stacks for the whole observable sky.

Now you see it, now you don't: Three images of a supernovae candidate.The first image shows a single frame exposure, with the object faintly visible. The second is a stack image, with all transient features removed from the field, so the supernovea cannot be seen. The third is a difference image of the first two, which clearly shows the bright exploding star (pictures courtesy of Queen's University Belfast, SN candidate 1100316261032829600). Credit: PS1SC
With near-Earth space increasingly littered with man-made objects, such as communications satellites, discarded old rockets and other space junk, our view of distant space is often obscured. These objects, which are relatively close to us, appear to move very fast relative to the distant stars and so appear in PS1 images as streaks across the frame. Because some of these streaks can potentially reveal information regarding the origin, as well as potential payload, of satellites, they are regarded as sensitive information by the United States Air Force, who funded the building of PS1. For this reason, one of the last stages of the IPP is to remove these streaks from all images released to consortium scientists.
While other PS1 systems have a chance to rest during daylight hours, the IPP marches on. Due to its commitment to process each nightâs data while simultaneously reprocessing older data with improved analysis software, the IPP works continuously. Tools are available for staff to monitor the load on the computer cluster, and to track the progress of each processing strand as it moves through the system. Different types of observation are given different priorities. For example, data for the MOPS system is high priority due to the time-critical nature of the potential discoveries of asteroids, which must be promptly followed-up by other telescopes for confirmation.
But regardless of survey, the IPP must, at the very least, complete processing of all new data before the following nightâs observations begin. To slip behind would be disastrous, as only bad weather, or technical issues at the summit, will slow the data flow.
As the volume of data grows over the coming years, the IPP will be under greater and greater strain, but additional computer hardware, as well as inevitable software changes, should ensure that it is able to keep up with demand, and continues to publish valuable data to scientists around the world.








